대학원 공부노트
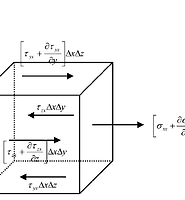
Hasegawa(1969) 1번 식 해설 4편(완) 본문

식이 복잡하므로 식을 전개한 뒤 우변을 둘로 나눠 정리하도록 한다.
이때
식이 여전히 복잡하므로 조금 더 전개한 뒤 3개로 나눠 살펴보도록 한다.
이 정도 하면 어느 정도 식이 눈에 들어오게 된다.
First, let's apply kronecker delta in our equation.
So we can simplify the equation like below.
At this point, let's bring the concepts gradient and divergence.
#1 Gradient
: Scalar function to Vector function
#2 Divergence
: Vector function to Scalar funtion
Before applying gradient and divergence with Einstein notation, bring the equation we used before.
if we assume
Now let's arrange the second term,
(다만, 이게 맞는 풀이인지 여전히 의문입니다.)
Then we can arrange the eqaution
Then the third term can be...
(세 번째 항도 이렇게 전개하는 것이 옳은건지 의문입니다.)
And let's apply vector calculus
We can also write this equation into this way
글을 작성하면서 suffix notation, kronecker delta and Levi-Civita tensor에 대한 학습이 추가로 이뤄져야함을 느낌.
Reference
Wikipedia, S wave
Wikipedia, Einstein notation
A Primer on Index Notation, John Crimaldi. August 28, 2006
네이버 블로그, 공부가 싫은 사람 「Gradient, Divergence and Curl in Suffix Notation」
'대학원 공부 > Hasegawa' 카테고리의 다른 글
| Hasegawa(1969) 5번 식 해설 (0) | 2022.08.16 |
|---|---|
| Hasegawa equation (0) | 2022.08.05 |
| Hasegawa(1969) 1번 식 해설 3편 (0) | 2022.07.29 |
| Hasegawa(1969) 1번 식 해설 2편 (0) | 2022.07.26 |
| Hasegawa(1969) 1번 식 해설 1편 (0) | 2022.07.25 |